Cotoha API を使ってみた

今回使ったもの
- requests (
pip install requests) – インターネットからHTMLを取り出すのに使う。 - BeautifulSoup (
pip install bs4) – スクレイピングに使う。 - cotohappy (
pip install cotohappy)- Cotohaに接続するのに使う。宣伝も兼ねているよ!
Cotohaとは?
公式ホームページには、「日本最大級の日本語辞書を活用、自然言語処理、音声認識APIプラットフォーム」とあります。インターネットを介して解析させたいテキストを送信し、形態素解析だったり、テキストどうしの類似度解析だったり、いろいろできます。
私は将来的に文書解析をしてゆきたいと考えているので、こう言ったものには目がありません。
JanomeとかMeCabとか、まあ様々なものに手を出してきましたが、このCotohaに関しては、文節(chunk)に分けるテキスト解析があったり、テキストの中からキーワードを出力してくれるという機能があるので、おすすめです。
ただ、開発者版(for Developer)は1日に1000リクエストしかできないので、本当は研究室で企業版(for Enterprise)をサブスクしてもらうか、NTTコミュニケーションズさんに学術版(for Academic)を作ってほしい!(勉強会で要望を出しといた、けど分からない)
早速使ってみた
ともあれ、使ってゆきましょう!
アクセストークンとかは伏字にしてあります。
登録ページは割と簡素で分かりやすくなっています。
メールボックスを確認すると、まあいろいろ質問されることがありますが、登録は書いてある通りにやればほんの10分間くらいでできると思います。
んで、クライアントIDとシークレットを手に入れた!

ということで、手に入れた情報とPythonを使ってテキストを解析させてゆきましょう!
import json
from pprint import pp
import requests
# https://api.ce-cotoha.com/home の
# Client ID って書いてあるところにあるやつ
client_id = 'aaaAAaaAaa00aAAAAaAaA00a0aAaAAAA'
# Client Secret って書いてあるところにあるやつ
client_secret = '0aAAaa00a0AaaAaa'
# Access Token Publish URL って書いてあるところにあるやつ
url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
# https://api.ce-cotoha.com/contents/reference.html の
# リファレンスにあるやつ。でも面倒だから書きたくないよね。
headers = {
'Content-Type': 'application/json'
}
data = json.dumps({
'grantType' : 'client_credentials',
'clientId' : client_id,
'clientSecret': client_secret
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
access_token = response['access_token']
# 解析させる文
sentence = 'すもももももももものうち'
url = 'https://api.ce-cotoha.com/api/dev/nlp/v1/parse'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Authorization': f'Bearer {access_token}'
}
data = json.dumps({
'sentence': sentence
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
# 辞書を見やすく整形して出力
pp(response)出力結果はこちら。
{'result': [{'chunk_info': {'id': 0,
'head': 1,
'dep': 'P',
'chunk_head': 0,
'chunk_func': 1,
'links': []},
'tokens': [{'id': 0,
'form': 'すもも',
'kana': 'スモモ',
'lemma': '李',
'pos': '名詞',
'features': [],
'dependency_labels': [{'token_id': 1,
'label': 'case'}],
'attributes': {}},
{'id': 1,
'form': 'も',
'kana': 'モ',
'lemma': 'も',
'pos': '連用助詞',
'features': [],
'attributes': {}}]},
{'chunk_info': {'id': 1,
'head': 3,
'dep': 'D',
'chunk_head': 0,
'chunk_func': 1,
'links': [{'link': 0, 'label': 'other'}]},
'tokens': [{'id': 2,
'form': 'もも',
'kana': 'モモ',
'lemma': '桃',
'pos': '名詞',
'features': [],
'dependency_labels': [{'token_id': 0, 'label': 'nmod'},
{'token_id': 3,
'label': 'case'}],
'attributes': {}},
{'id': 3,
'form': 'も',
'kana': 'モ',
'lemma': 'も',
'pos': '連用助詞',
'features': [],
'attributes': {}}]},
{'chunk_info': {'id': 2,
'head': 3,
'dep': 'D',
'chunk_head': 0,
'chunk_func': 1,
'links': []},
'tokens': [{'id': 4,
'form': 'もも',
'kana': 'モモ',
'lemma': '桃',
'pos': '名詞',
'features': [],
'dependency_labels': [{'token_id': 5,
'label': 'case'}],
'attributes': {}},
{'id': 5,
'form': 'の',
'kana': 'ノ',
'lemma': 'の',
'pos': '格助詞',
'features': ['連体'],
'attributes': {}}]},
{'chunk_info': {'id': 3,
'head': -1,
'dep': 'O',
'chunk_head': 0,
'chunk_func': 0,
'links': [{'link': 1, 'label': 'other'},
{'link': 2, 'label': 'adjectivals'}]},
'tokens': [{'id': 6,
'form': 'うち',
'kana': 'ウチ',
'lemma': '内',
'pos': '名詞',
'features': ['連用'],
'dependency_labels': [{'token_id': 2, 'label': 'nmod'},
{'token_id': 4,
'label': 'nmod'}],
'attributes': {}}]}],
'status': 0,
'message': ''}
この結果を見ると、ちゃんと、「すもも」「もも」「もも」「うち」が名詞で分類されていること、「すももも/ももも/ももの/うち」と文節分けされていることが分かりますね。やったね!
でも見づらいわ!
CotohapPyを開発する
「ないなら、作れば良いじゃない」と、かのマリー・アントワネットも言っていたので(言ってない)、見やすくするためにCotohapPyというものを開発してみた。ちなみに、pipできるようにしときました。
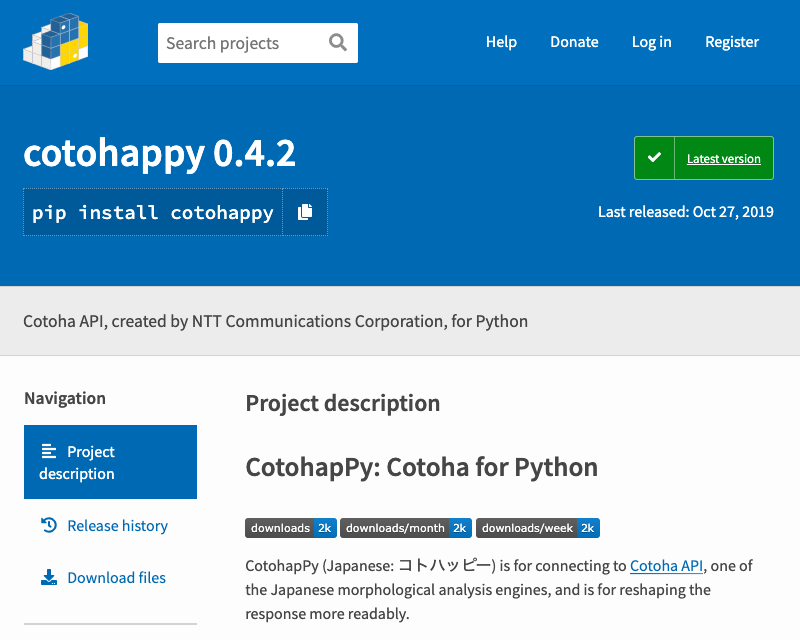
なんと約5日間で2.8kインストール突破!
私の予想では、「私がテスト用にインストールするにしても合わせて30インストールくらいかなあ」だったのですが、その2ケタくらい上を行きました。歓喜!
もちろん、これからもエラー箇所とか「こういうのあったらいいな」とかあれば、順次アップデートしてゆきますので、応援も支援もよろしくお願いします! プログラマー大歓迎ってところです笑
読み方は「コトハッピー」です。「ハ」がアクセントです。「Cotoha」は「コトハ」で「コ」にアクセントがありますけど、これとは違うと考えてください。私がCotohapPyの公式なので間違いないです笑
ところで、JSONは2タブイメージなんだよね。Pythonは4タブイメージだけど。
{
"AccessTokenPublishURL": "https://api.ce-cotoha.com/v1/oauth/accesstokens",
"APIBaseURL" : "https://api.ce-cotoha.com/api/dev/",
"ClientId" : "aaaAAaaAaa00aAAAAaAaA00a0aAaAAAA",
"ClientSecret" : "0aAAaa00a0AaaAaa"
}
import cotohappy
if __name__ == '__main__':
coy = cotohappy.API()
print('\n#### parse origin ####')
sentence = 'すもももももももものうち'
kuzure = False
parse_li = coy.parse(sentence, kuzure)
for parse in parse_li:
print(parse)
print('\n#### parse tokens ####')
for parse in parse_li:
for token in parse.tokens:
print(token)で、出力結果はこんな感じ(2019年10月28日現在)
#### parse origin ####
すももも 0,1,P,0,1,*,*,*,*,*
ももも 1,3,D,0,1,*,*,*,*,*
ももの 2,3,D,0,1,*,*,*,*,*
うち 3,-1,O,0,0,*,*,*,*,*
#### parse tokens ####
すもも 0,スモモ,李,名詞,*,*,*,*,*
も 1,モ,も,連用助詞,*,*,*,*,*
もも 2,モモ,桃,名詞,*,*,*,*,*
も 3,モ,も,連用助詞,*,*,*,*,*
もも 4,モモ,桃,名詞,*,*,*,*,*
の 5,ノ,の,格助詞,連体,*,*,*,*
うち 6,ウチ,内,名詞,連用,*,*,*,*めっちゃ見やすくなった!
余談ですが
「なぜ、CotohapPyのインスタンスを公式でcoyと宣言しているのか。apiではないのか」という些細なことですが、理由は2つあります。
- CotohapPyの最初の2文字、最後の1文字をとって略した
- 新海誠監督の映画「言の葉の庭」からの連想ゲーム
まず、最初の理由は単純ですね。TensorFlowだってtfとかTkInterだってtkって略すでしょう。それと同じです。
2つ目の理由ですが、私は新海誠監督の映画が好きなので(結構前のブログでも言ってた気がする)それにあやかっています。「Cotoha→コトハ→言の葉の庭」みたいな。公式のキャッチコピーに「”愛”よりも昔、”孤悲”のものがたり」とあったので、その「孤悲」の部分をとったしだいです。
で、「言の葉の庭」のストーリーをスクレイピングして解析させた結果の例は、PyPIのCotohapPyのページに書いてあります。良かったら試してみてください。くれぐれも、payload.jsonをお忘れなく。
さいごに
CotohapPyの記述例はここに上げといてあるので、分からなければ、参照してほしいです。
公式ドキュメントに日本語のものは作っていません。面倒なのでできるだけグローバルに生きてゆきたいと考えているので。本当は面倒なだけです。
- 前の記事

Pythonの変数アノテーション 2019.10.12
- 次の記事
Pythonでステレオ音源を作成する 2019.12.02