日本語グライド入力方式jaGlide開発記
いきなりですが、グライド入力ということばをご存知ですか?
まあ、このサイトを見つけたからには、「日本語 グライド入力」と入れたんだろうし、そういう人はだいたい知ってるとは思いますが。
3つ大事なことを言っておきます。
- 2021年1月8日現在、日本語のグライド入力はありません。どんなにググっても出てこないので、「日本語でグライド入力したいのにっ!」っていう人は諦めましょう
- この記事はそんな日本語では現状存在していないグライド入力を作るというプロジェクトを1人で勝手に立ち上げているという話です。「プログラミングとかやったことないし、生涯やることはないんだろうな」という人は、「世の中にはこんなわけのわからないことをしている人がいるんだなあ」程度に留めてください
- 「私も日本語のグライド入力を開発中で、お手伝いしますよ!」という人はぜひ私のTwitterのリプライにご一報ください。現状つまずいている私としては感謝してもしきれません。
開発経緯
スマートフォンを使う場合、日本語の入力の方法には主にトグル入力、フリック入力、キーボード入力があります。
トグル入力というのは、例えば、「あんがい」と打ちたい場合は「1,000,2*,11」みたいな感じです。スマホ以前のフィーチャーフォンを使っていた世代ではトグル入力が主流だと思います。
フリック入力というのは、スマホを使っている比較的若い世代の人たちでは主流かもしれません。「あんがい」の場合では「1・,0↑,2・*・,1←」のように指をフリックさせながら五十音を操作して入力する方法です。
一方で、フリック入力もトグル入力も使いたくないという人もいます。パソコンなどのキーボードでローマ字入力するのと同じようにしたいという人は、これが主流だと思います。「あんがい」の場合はキーボードで「angai」のように打ちますね。
しかしながら、現在スマホで入力する方法は、世界的に見ればグライド入力が主流です。英語の”glide”とは日本語で「を滑らせる」の意味があります。
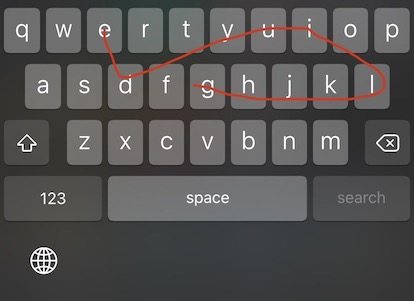
この入力方法は、一般的なキーボードの入力である1文字ずつキーを打って入力するのとは異なり、例えば”glide”と入力する場合は、下の図のようになぞります。
こうするとあら不思議! なんと”glide”と入力されます!
英語版のキーボードで試してみてください!(Androidは早くから対応していて、iPhoneでも最近できるようになった)
なぜ日本語グライド入力方式がないのか
が実は、日本語のキーボードにはこのグライド入力がないんです。
中国語にはあるのにね!(図は日本語に訳すと「なぜ」。中国語はちょっとだけやってたが、今は聞き取るのが精一杯)
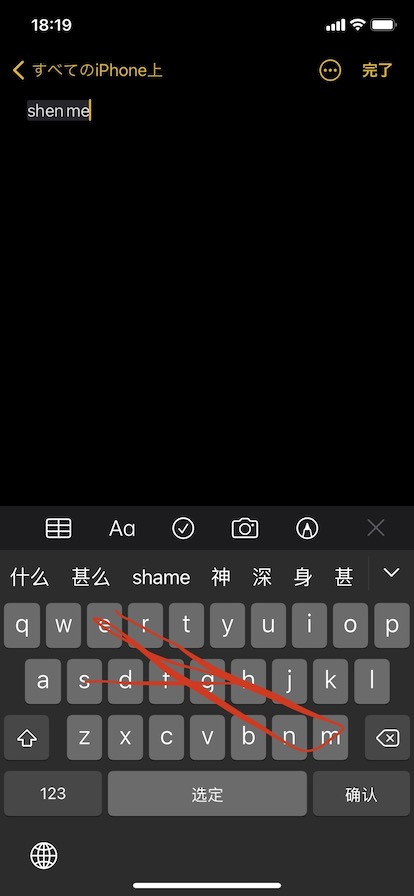
調べてみるとわかりますが、iPhoneでは他に韓国語も対応していないらしい(図は日本語に訳すと「感謝します、ありがとう」。韓国語に関して、Appleはそこらへん無能だが、Googleはそこらへん有能なので対応している。韓国語は最近韓ドラを見始めているのでちょっとだけ聞き取れるようになった)
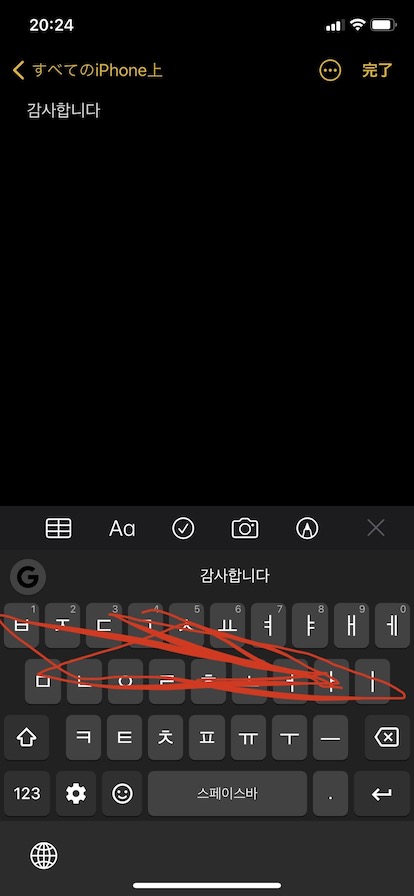
「gboardならあるやろ」と思ってiPhoneにインストールしてみたけど、やっぱりダメ。
Quoraでも色々説明していますが、ちょっと私にはよくわかりません。
あと、ASCIIでも議論されてた。
それなら作ろう
まあ、これがうまくいけば、なんやかんや研究題材になるのでは? という感じで作りました。
そこで作ることにしたのが、「日本語グライド入力方式キーボード(jaGlide、Glide typing keyboard for JApanese language、ジェイ・グライド)」です。
データを取る
まず、iPhoneでデータを取ります。ここらへんは実装とか面倒なので、Swiftで画像を埋め込んで、なぞった座標を取り出すプログラムを書きました(iPhoneでデータを取ってから1週間以上経ったので、アプリが起動しないので画像は割愛)
「今日の天気は晴れです(kyou no tenki ha hare desu)」となぞります。
Pythonで座標データをローマ字に落とし込む
Swift上で全部やろうかと考えましたが、書いている途中で「あ、私そこまでSwiftちゃんと書けないわ」となったので、諦めてPythonで書きました。
ただの座標変換なので、そんなに大変ではないです。
x,y,begun
635,252,1
621,241,0
617,238,0
607,230,0
595,222,0
...
528,156,0
529,156,0
530,156,0
531,156,0
534,162,0で、変換プログラムがこれ。
import re
import json
from cairosvg import svg2pdf
import os
with open('keys_xy.json', mode='r') as f:
keys_xy_dic = json.load(f)
for key in keys_xy_dic:
keys_xy_dic[key] = [range(*val) for val in keys_xy_dic[key]]
def xy2key(x: int, y: int) -> str:
for key, (x_rng, y_rng) in keys_xy_dic.items():
if x in x_rng and y in y_rng:
return key
else:
return ''
def csv2str_li(keys: str) -> [str, ...]:
xy_li_li = []
with open(fname, mode='r') as f:
_xy_li_li = []
for line in f.read().split('\n')[1:]:
line_li = [int(val) for val in line.split(',')]
if line_li[2] == 1:
xy_li_li.append(_xy_li_li)
_xy_li_li = []
_xy_li_li.append(line_li[:2])
xy_li_li.append(_xy_li_li)
xy_li_li = xy_li_li[1:]
str_li = []
erace_convolve_keys = lambda val: f'B{val}E'
for xy_li in xy_li_li:
str_li.append(erace_convolve_keys(''.join(xy2key(*xy) for xy in xy_li)))
return str_li
if __name__ == '__main__':
from glob import glob
fname = glob('*kyou*.csv')[0]
str_li = csv2str_li(fname)
print('\n'.join(str_li))keys_xy.jsonってのは、判定するキーの矩形情報を収めたファイルです。こんな感じ。
{
"q": [[ 8, 80], [106, 230]],
"w": [[ 92, 162], [106, 230]],
"e": [[174, 244], [106, 230]],
"r": [[256, 326], [106, 230]],
"t": [[338, 408], [106, 230]],
"y": [[420, 490], [106, 230]],
"u": [[502, 572], [106, 230]],
"i": [[584, 654], [106, 230]],
"o": [[666, 736], [106, 230]],
"p": [[748, 818], [106, 230]],
"a": [[ 8, 80], [218, 308]],
"s": [[ 92, 162], [218, 308]],
"d": [[174, 244], [218, 308]],
"f": [[256, 326], [218, 308]],
"g": [[338, 408], [218, 308]],
"h": [[420, 490], [218, 308]],
"j": [[502, 572], [218, 308]],
"k": [[584, 654], [218, 308]],
"l": [[666, 736], [218, 308]],
"-": [[748, 818], [218, 308]],
"z": [[134, 204], [330, 420]],
"x": [[216, 286], [330, 420]],
"c": [[298, 368], [330, 420]],
"v": [[380, 450], [330, 420]],
"b": [[462, 532], [330, 420]],
"n": [[544, 614], [330, 420]],
"m": [[626, 696], [330, 420]]
}結果はまあ良い感じになってます。
BkkkkiuuuuuyyyyyuuuiiioooopppppooooiiiuuuuuuuuuE
BnnnnkklooooooooooooE
BtttttrrrreeeeeeeeeeeeerrrrrtttghhhhbbbbnnnnnnnnnnnnnnnnnnnnnkkkkkkkkkkkkkkkiiiiiiiiiiiiiiE
BhhhhggggfffddsssaaaaaaaaaaE
BhhhggfddsssaaaaaaaaaaaaaaaassseeerrrrrrrrrrrrrrrrrrrrreeeeeeeeE
BdddddeeeeeeeeeeeeeeeeeeeeeeedssssdddffttyyyyuuuuuuuuuuuuuuEBとEってのは、始まりと終わり(Begin, End)を表す文字です。
Pythonで謎のアルファベット羅列を短くする
ここらへんはまだ研究段階なので、もうちょい良いデータが集まり次第、報告します。
most candidatable: input romaji
kyou : kkkkiuuuuuyyyyyuuuiiioooopppppooooiiiuuuuuuuuu
no : nnnnkkloooooooooooo
teni : tttttrrrreeeeeeeeeeeeerrrrrtttghhhhbbbbnnnnnnnnnnnnnnnnnnnnnkkkkkkkkkkkkkkkiiiiiiiiiiiiii
ha : hhhhggggfffddsssaaaaaaaaaa
hare : hhhggfddsssaaaaaaaaaaaaaaaassseeerrrrrrrrrrrrrrrrrrrrreeeeeeee
desu : dddddeeeeeeeeeeeeeeeeeeeeeeedssssdddffttyyyyuuuuuuuuuuuuuu上の結果を見れば分かるとおり、精度はあまり良くないです。
おわりに
今回は日本語のグライド入力を開発することを目的に試行錯誤しました。
ここまでに2週間くらいかかった。
やってみてわかりましたが、日本語のグライド入力はこれ自体で研究課題になります。
文章を学習させたり、構造木を作ったり、なんやかんやしたら結構大変でした。
が、私がしたいことはもっと違うことなので、これは暇つぶし程度にまたゆっくり進めてゆきます(完成している頃には思念入力みたいなもっと画期的なものが出来てるかもしれないね)
- 前の記事

Nocca NoccaをPythonで組む 2020.11.22
- 次の記事

NHK番組APIのPythonラッパーを作った 2021.02.21