スクレイピング対策対策をした話
タイトルですが、打ち間違えではないです。「対策対策」で合っています。「めちゃ²イケてるッ!」みたいな感じです。
機械学習をさせるためなどに、よく「大量に画像を収集したい」ってなることがあると思う。もちろん、URLを単純に指定して、画像が取り出せればそれで良い。
しかしもし、それができない場合、どうするべきだろうか? 今回は、スクレイピング対策されたページで画像を集めるにはどうすれば良いか、検証してゆきたいと思う。
※注意※
Twitterなど、「明示的にスクレイピングが禁止されているページ」では、スクレイピングはやってはいけません。スクレイピングをする前に、必ず規約等を確認してください。
スクレイピング対策されていた話
ある日、私は大量に画像を収集するために、「いちいちクリックなんて面倒だ。よし、スクレイピングで画像を収集させよう!」と考えた。Pythonでコードを書き、早速プログラムを実行した。
# sample0.py
import requests
from time import sleep
target_urls = []
# ここでurlを取得しリストにまとめる
for i in range(len(target_urls)):
img_bin = requests.get(target_urls[i]).content
sleep(1)
target_jpg = "resources/sample%d.jpg"%i
with open(target_jpg, mode="wb") as file:
file.write(img_bin)が、
.
0 directories, 0 files画像は収集されていなかった。どういうことなのか検証していると、リンクを直接指定したときに、このような表示が出てきた。
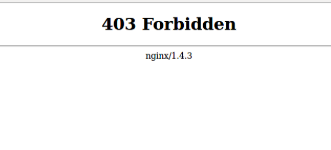
Nginx(公式リンクはここ)
こんな不条理な画面が出てくるとはつゆ知らずだった当時の私は、「Nginxとはなんぞや?」と思い、とりあえず「Nginx スクレイピング」とググってみた。
するとまあ出てくる出てくる。「スクレイピング対策」「bot対策」云々。
NginxはNginx inc.のIgor Sysoevによって開発された、フリーでオープンソースのウェブサーバーである。確かウィキペディアにもそんな感じのことが書いてあった気がする。
どうやら、Nginxというのは、スクレイピング対策に使われているものらしい。悪意のあるスクレイパーが404を踏みまくったり、1秒に1ページ超アクセスしたりをするせいでサーバーに負荷がかかる。これに対策すべく、導入されているのだとか。
「なるほど、それなら手動で画像を収集するしかないな」となればそれで済んだのかもしれない。でもそんな面倒なことをやりたくない、そう思った。これがスクレイピング対策対策を始めたきっかけだった。
打倒Nginx
Nginxと対峙すべく、様々な手法を考えてはまた、「これは無理だ」と切り捨てた。
「指の動きを完全再現しよう」「ページに2回以上連続でアクセスすればできるのでは?」とか、コードとにらめっこをしながら闘った。
しかし、どれもこれもダメだった。出てくるのは403。またしても空のディレクトリー。
散々コードを書き換えては実行して失敗して消してググってを繰り返しているうちに、行き着いた先はこれだった。
Seleniumによるスクレイピング
画像をダウンロードするのに、私はrequestsを用いていた。Python2でスクレイピングをしていたことがある人は知っていることだろう。Python3ではurllib.requestの方が便利だし、そっちを使ってみたりもしたが見事に失敗。
そして、1つの答えがSeleniumだった。
Seleniumというのは、「ウェブアプリケーションのテスト自動化を実現するブラウザー駆動型テストツール群」とオープンソースの自動テストツール/Seleniumとはには書いてあった。
私は「これも失敗に終わるかもしれない」と半ば諦めながらこれを導入することにした。コード例は以下のような感じである。
# sample1.py
from time import sleep
import pyautogui as pgui
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
target_url = ""
driver = webdriver.Chrome("./chromedriver")
driver.get(target_url)
soup = BeautifulSoup(driver.page_source, "html.parser")
for i in range(5):
#xpathをここで指定する
target_xpath = ""
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(Keys.TAB)
actions = ActionChains(driver)
actions.context_click(element)
actions.perform()
pgui.typewrite(["down" for i in range(5)])
pgui.typewrite(["enter"])
pgui.typewrite(["enter"])
掻い摘んで説明すると、
- PythonでChrome Driverを開く
- TABキーを入力させて画像の位置まで「指」を持ってくる
- コンテキストクリックをさせる
- 画像保存動作をさせる
「こんな面倒なことをしないと画像が保存できないの?」となる気持ちは分かる。しかし、背に腹はかえられぬ。手動でやるよりはずっとマシだ。
スクレイピング対策対策をしてみて
これでやっと画像を自動収集させることができるようになった。
しかし、ITは常に進化している。今日できたことも明日できなくなっているなんてザラである。
たとえ歴史学者が「将軍時代といえば、つい最近のことですが」と言おうと、プログラミングに関する知識を記録・共有するためのサービスには「この記事は最終更新日から1年以上が経過しています」と煽ってくる。
壁にうち当たったらどう対処するべきか。このスクレイピング対策対策を通して、私は考える機会をもらった。そう思った。
- 前の記事

Pythonで始めるDIY 第1章終 寿司打を自動化してみよう! 2019.04.08
- 次の記事
BeautifulSoupだけを使って歌詞をスクレイピングしたい 2019.05.08