Pythonで始めるDIY 第1章(2)寿司打を自動化してみよう!

重要な追記(2020年7月30日)
寿司打WebGL版の正式なQ&Aを見ていただくとわかりますが、現在ではこうした自動化ツールの利用を禁止しているようです。
このサイトで書かれていることは「過去にはこんなことがあったんだな」程度で留めておいてください。
本題
前回の続きです。
前回までのあらすじ
前回はスタートボタンをクリックするところまで実装しました。今回は、「お勧めコースをクリックして、文字を入力させる」ところまで実装してゆきたいと思います。
階層構造は前回と同様、このようになっています。
|--main.py
|--chromedriverそれでは、初めてゆきます。
3. 文字を入力させる
最初に、お勧めコースのボタンをクリックさせます。これは前回の復習も兼ねています。書き換えるとしたらこんな感じになると思います。
# main.py
...
print("スタートボタンをクリックしました。")
# ボタンが表示されるまで待つ
sleep(2)
# お勧めコースをクリックする
actions = ActionChains(driver)
actions.move_to_element_with_offset(webgl_element, center_x, center_y).click().perform()
print("お勧めコースのボタンをクリックしました。")
input("何か入力してください")
...実行してみて、ちゃんとクリックされましたか?
では次に、キーを入力させます。試しに、ゲームスタートできるキーであるスペースキーを入力させましょう。
# main.py
...
print("お勧めコースのボタンをクリックしました。")
# <body>に向かってキーを入力させる
target_xpath = '/html/body'
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(" ")
input("何か入力してください")
...実行してみると、こうなると思います。
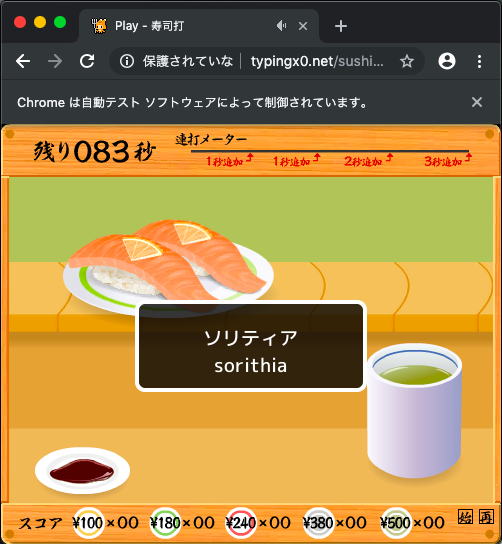
無事、ゲームを開始させることができました!
さて、文字の入力にはelement.send_keysを使うことが分かったところで、次に文字を入力させてゆきたいと思います。
とりあえず、文字はテキトーに入力させてみましょうか。
# main.py
...
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(" ")
# 時間を計測
from time import time
start = time()
while time() - start < 90.0:
# 文字をテキトーに入力
element.send_keys("abcdefghijklmnopqrstuvwxyz-!?.,")
input("何か入力してください")
...こんな感じで入力できていると思います。
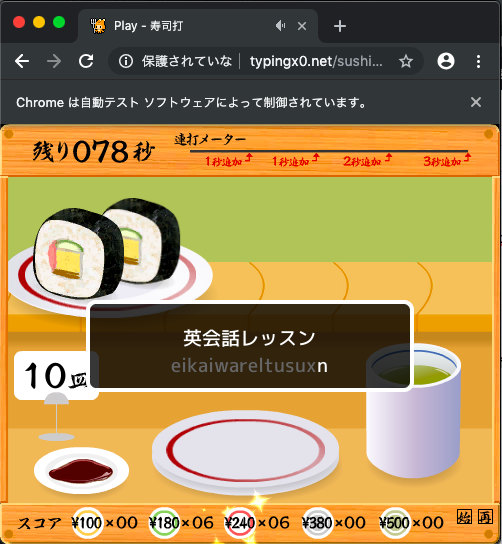
画像は「英会話レッスン/eikaiwareltusuxn」でちゃんと入力されていますね。
では結果はどうだ?
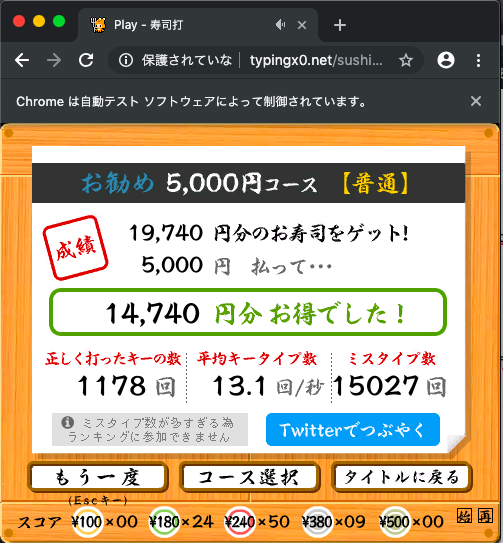
19740円、めちゃくちゃお得な結果になってます!
でもちょっと待ってください。ミスタイプ数「15027回」と表示されています。これはまずい。
みなさんもプログラムを動かしているときに気づいたことでしょう。そう、テキトーに入力しているだけでは、テキトーな結果しか出てきません。
ではどうしよう。ちゃんとした文字を入力させることを次に考えましょう。
4. スクショを撮る
スクレイピングという言葉を知っている人はおそらく「どうせHTML上に文字データとかが保存されているんだろ」とか思ったかもしれません。
ですが、残念ながら、単なるスクレイピングでは寿司打に勝てません。
実は寿司打はOpenGLというものを使っていまして(OpenGL版を使っているのだから当然ですが)、これはグラフィックスハードウェア向けの2D、3DCG用のライブラリーとなっています。
文字データまで画像(映像)化されているんです。だからそのままの文字を取り出して、そのままその文字を出力するということはできません。
OpenGL(公式ページはここ)
方式としては、「画面をスクショして、文字の部分だけを取り出して、その文字を認識する」というプロセスを踏む必要があります。ああ大変!
ではそれを実装してゆきます。
# main.py
...
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(" ")
# ファイル名
fname = "sample_image.png"
# スクショをする
driver.save_screenshot(fname)
# 時間を計測
from time import time
start = time()
# while time() - start < 90.0:
"""
!!この部分は消す!!
# 文字をテキトーに入力
element.send_keys("abcdefghijklmnopqrstuvwxyz-!?.,")
"""
input("何か入力してください")
...これを実行すると、main.pyと同じ階層にsample_image.pngという画像が生成されます。
|--sample_img.png
|--main.py
|--chromedriverではそのファイルを開いてみましょう。

こんな感じでスクショが保存されていると思います。このコードの方式を使って文字を取り出してゆきます。
5. 文字を認識する
さあ、いよいよ大詰めとなってきました。
一気に飛ばしてしまいますが、コードはこんな感じになっています。
# main.py
...
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(" ")
from PIL import Image
import pyocr
import pyocr.builders
# PyOCRのツール
tool = pyocr.get_available_tools()[0]
from time import time
start = time()
while time() - start < 90.0:
# 移動した
# ファイル名
fname = "sample_image.png"
# スクショをする
driver.save_screenshot(fname)
# 画像をPILのImageを使って読み込む
# ローマ字の部分を取り出す
im = Image.open(fname).crop((0,230,500,254))
# tool で文字を認識させる
text = tool.image_to_string(im, lang='eng', builder=pyocr.builders.TextBuilder())
# text を確認
print(text)
# 文字を入力させる
element.send_keys(text)
input("何か入力してください")
...文字を認識させるために、PyOCRとPILをインポートします。tool.image_to_stringで画像から文字を認識させます。
これによって変数textに認識した文字が入ります。これをelement.send_keysで入力させます。ではこれを実行してみましょう。ログは以下のようになります。
スタートボタンをクリックしました。
お勧めコースのボタンをクリックしました。
BU EY A Te AE ESI ED
arumaziro
omamagoto
yakizakana
konekotyann
asuparagasu
nettaigyo
syunbunnnohi
matigaisagasi
ftsaa leu eth)
fsva leet eihe)
fsva leet eihe)
fsva leet eihe)
fsva leet eihe)
fsva leet eihe)
nebousityatta
kentouwoinoru
makkanataiyou
ant nettaiteikiatu
ant sotugyousyasinnログを見ると分かる通り、あやふやなテキストを認識しているところもあれば、ちゃんと読み取っている場所もあります。認識率はこれから上げてゆきます。
次回予告等
今回は認識させた文字を入力させるところまで実装しました。
これでも十分高いスコアは出ますが、もっと高いスコアを出したいですよね?
次回は「精度を上げる」ことをやってゆこうと思います。
今回までのコード例
ここまでで、コードは以下のようになります。参考にしてみてください。
# main.py
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from PIL import Image
import pyocr
import pyocr.builders
# Chrome Driverのパス
driver_path = './chromedriver'
# ドライバーを開く
driver = webdriver.Chrome(driver_path)
# ウィンドウサイズを固定
# +123としているのは
# 「Chromeは自動テストソフトウェアによって制御されています。」
# という部分を考慮している
window = (500, 420+123)
driver.set_window_size(*window)
# OpenGL版の寿司打を開く
target_url = 'http://typingx0.net/sushida/play.html'
driver.get(target_url)
# 寿司打のゲーム画面をずらすために書く
target_xpath = '//*[@id="game"]/div'
webgl_element = driver.find_element_by_xpath(target_xpath)
actions = ActionChains(driver)
actions.move_to_element(webgl_element).perform()
# クリックする前にロード時間待機
sleep(10)
# スタートボタンの座標
center_x = 250
center_y = 256
# スタートボタンをクリックする
actions = ActionChains(driver)
actions.move_to_element_with_offset(webgl_element, center_x, center_y).click().perform()
print("スタートボタンをクリックしました。")
# ボタンが表示されるまで待つ
sleep(2)
# お勧めコースをクリックする
actions = ActionChains(driver)
actions.move_to_element_with_offset(webgl_element, center_x, center_y).click().perform()
print("お勧めコースのボタンをクリックしました。")
# <body>に向かってキーを入力させる
target_xpath = '/html/body'
element = driver.find_element_by_xpath(target_xpath)
element.send_keys(" ")
# PyOCRのツール
tool = pyocr.get_available_tools()[0]
from time import time
start = time()
while time() - start < 90.0:
# 移動した
# ファイル名
fname = "sample_image.png"
# スクショをする
driver.save_screenshot(fname)
# 画像をPILのImageを使って読み込む
# ローマ字の部分を取り出す
im = Image.open(fname).crop((0,230,500,254))
# tool で文字を認識させる
text = tool.image_to_string(im, lang='eng', builder=pyocr.builders.TextBuilder())
# text を確認
print(text)
# 文字を入力させる
element.send_keys(text)
input("何か入力してください")
# ドライバーを閉じる
driver.close()
driver.quit()- 前の記事

Pythonで始めるDIY 第1章(1)寿司打を自動化してみよう! 2019.04.08
- 次の記事
Pythonで始めるDIY 第1章終 寿司打を自動化してみよう! 2019.04.08